L'evoluzione del Web
La vita moderna pianta fortemente le sue radici su internet, influenza e determina il modo in cui ci comportiamo in maniera persistente. Ma il web non è sempre stato così.
L’evoluzione del Web
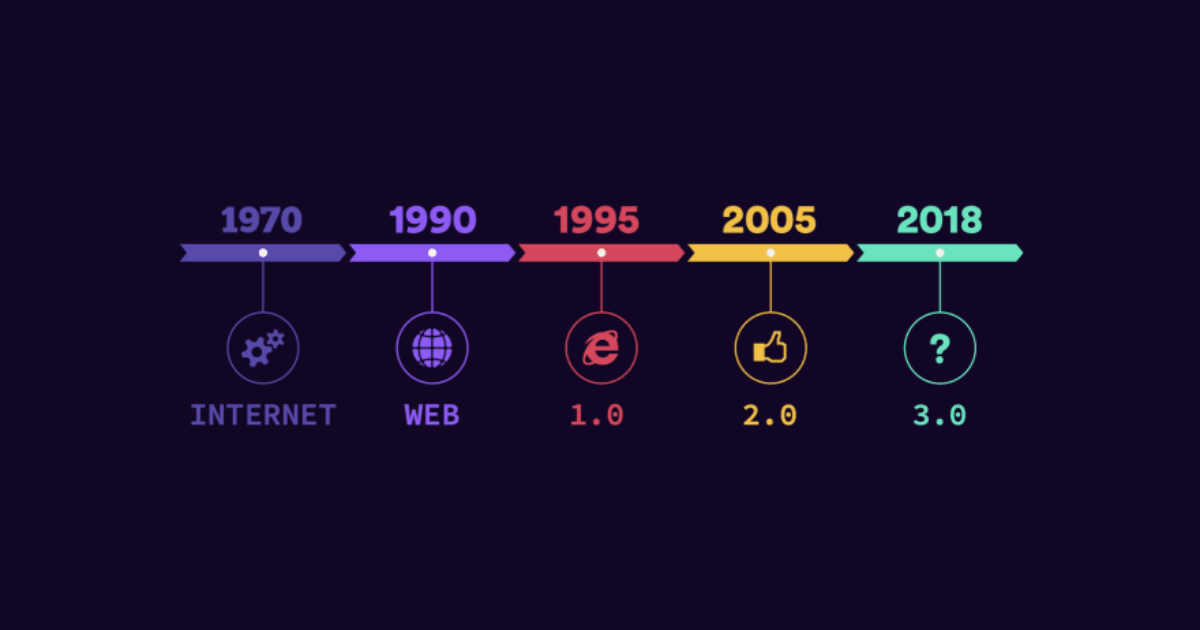
Negli ultimi 30 anni il Web si è evoluto in maniera vertiginosa, non solo da un punto di vista estetico, ma anche applicativo e concettuale. Storicamente viene diviso in 3 fasi:
- Web 1.0: circa dal 1991 al 2004
- Web 2.0: dal 2004 ad ora
- Web 3.0: dal pochi anni ad ora
La transizione tra queste fasi ovviamente non è netta, non esiste una data sul calendario in cui si è passati dal Web 1.0 al Web 2.0.
Cosa è il Web 1.0?
Questa è la prima fase del Web (leggermente diverso dal concetto di internet, che esisteva da prima del Web 1.0, si pensi ad IRC). Gli utenti che partecipavano, che lo utilizzavano, erano puri spettatori. Non esisteva interazione, tutti i siti erano delle vetrine statiche e l’unica cosa che si poteva fare era leggere e riprodurre contenuti presenti in quella pagina. L’unica forma di interazione che si associa al Web 1.0 sono i primi forum, un concetto estremamente lontano dai social network a cui siamo abituati oggi.
Non si poteva essere creatori, ma solo spettatori. Il ruolo di creatore era riservato agli sviluppatori. Non esistevano metodi semplici per creare contenuti sul web (post su Instagram, pagine Facebook, ecc.).
Cosa è il Web 2.0?
Il Web 2.0, anche noto come Web2, è quello che la maggior parte di noi ha utilizzato per la prima volta, il nostro primo approccio ad internet. Il Web2 è considerato il Web Sociale, caratterizzato da una immensa possibilità di essere creatori di contenuti senza dover avere competenze di programmazione. Le applicazioni, come ogni social network, sono sviluppate per far si che chiunque possa partecipare alla modellazione e alla creazione di nuovi contenuti nel Web2. Ed è proprio questa semplicità che ha reso popolare il Web.
Monetizzazione nel Web 2.0
Cerchiamo di ricordare come sono nati i primi social network: Instagram, Facebook, Twitter o YouTube. I passaggi sono sempre gli stessi:
- L’azienda lancia l’app
- Si cerca di attrarre più persone possibili e stabilire una user-base
- Si monetizza la user-base
La maggior parte delle compagnie come prima cosa cerca di rendere il servizio il più semplice possibile, niente pubblicità invasive e Ads di alcun genere. Il primo obiettivo è far iscrivere più persone possibile, diventare un cult. Una volta che il cult si è affermato, allora è arrivato il momento di monetizzare, di trarre profitti dall’investimento fatto.
Spesso per monetizzare e sopravvivere vengono introdotti investitori esterni. Ma chi investe in un progetto, poi pretende risultati da quella azienda, vuole un beneficio di tipo economico. E la storia spesso ci insegna che questo porta sempre a svantaggi da parte dell’utente, un peggioramento dell’esperienza generale.
Uno dei modi più comuni e proficui con cui monetizzare grandi progetti come quelli dei social network è la vendita dei dati personali. Per molte compagnie che vivono sul Web2, come Google e Facebook, avere più dati vuol dire più Ads personalizzati. Che portano a più click e più guadagni. Ed è questa la base fondamentale su cui si basa il Web2: la centralizzazione di enormi quantità di dati, divisi in data-center in mano alle Big Tech companies. La centralizzazione dei dati porta a problemi di sicurezza, principalmente caratterizzati dai così detti data-breaches.
Il Web3 nasce con lo scopo ben preciso di risolvere questi problemi, ridisegnando i fondamentali dell’architettura di internet e su come gli utenti interagiscono con le applicazioni.
Cosa è il Web 3.0
La differenze tra il Web2 e il Web3 sono tante, ma il concetto alla base è uno solo: decentralizzazione.
Questa parola riecheggia da qualche anno su internet ogni volta che si parla di blockchain e crypto valute. Ma come la si applica a questa nuova idea di Web?
Il Web 3.0 migliora il concetto di internet così come lo conosciamo oggi aggiungendo delle caratteristiche chiave. Il Web3 deve avere soddisfare questi parametri:
- Verificabilità
- Assenza di doversi fidare di intermediari (trustless)
- Self-Governing
- Permissionless
- Distribuito e robusto
- Pagamenti nativi
Andiamo a vedere questi paroloni cosa vogliono dire. La grossa differenza lato sviluppo è che un developer non creerà più applicazioni che vengono eseguite su un singolo server che salva i dati in un singolo database (che di norma a sua volta è hostato e gestito da un singolo cloud provider).
Adesso le applicazioni Web 3.0 verranno eseguite su blockchain, network decentralizzati con svariati nodi (server) peer-to-peer. O in generale, una combinazione del vecchio metodo con questo più moderno. Spesso queste applicazioni vengono chiamate Dapps, ovvero decentralized applications.
Quando sentiamo parlare di Web3, il discorso è sempre accompagnato dalle crypto valute. Queste giocano un ruolo fondamentale all’interno di questi protocolli. Garantiscono un incentivo economico (token) per chiunque voglia partecipare nel creare, governare, contribuire o migliorare uno di questi progetti.
Questi protocolli di norma offrono una svariata scelta di servizi che fino ad ora, erano garantiti solo dai grandi cloud provider: computing, storage, banda, identità, hosting etc. Nel Web3 la storia cambia radicalmente: i soldi (o meglio, la currency) spesi per determinati servizi non vanno ad un singolo ente centralizzato, ma vengono distribuiti direttamente a tutti i validatori del network sotto forma di gas-fees. Anche protocolli su blockchain native come Ethereum operano in questa maniera.
Pagamenti nativi
I Token di cui abbiamo appena parlato introducono anche il layer dei pagamenti nativi. Un sistema senza frontiere di stati o intermediari di terze parti.
Fino ad ora, aziende centralizzate come Stripe e PayPal hanno fatto miliardi di dollari gestendo i pagamenti online. Questi metodi però non hanno la libertà e la interoperabilità che si riesce a raggiungere tramite blockchain. Inoltre questi servizi richiedono necessariamente l’inserimento dei nostri dati personali per poter eseguire operazioni.
All’interno di applicazioni Web3, delle Dapps, è possibile integrare un Crypto Wallet. Il più famoso è per esempio MetaMask (nulla a che vedere con Meta, ex Facebook).
Per quanto riguarda l’utilizzabilità e la semplicità dei pagamenti all’interno delle blockchain, è un discorso molto più complesso che non tratteremo in questo articolo. Il concetto che ci interessa è questo: a differenza dell’attuale sistema finanziario moderno, gli utenti all’interno del Web3 non devono passare attraverso svariati sistemi intricati di identificazione per usufruire un servizio finanziario. Tutto quello che serve è avere un Wallet che supporta il network con il quale vogliamo interagire e possiamo inviare e ricevere pagamenti, senza bisogno dell’approvazione di una banca o di una compagnia esterna.
Una nuova idea di costruire aziende
Con l’introduzione dei Token, nasce il concetto di tokenizzazione e realizzazione della token economy.
Cerchiamo di capire con un esempio semplice come funziona. Supponiamo di voler creare un’azienda, per poter mettere in atto questa idea che abbiamo avuto abbiamo bisogno di soldi per pagare sviluppatori e tutto ciò di cui avremo bisogno.
Allo stato della finanza attuale, di norma si assume un venture capital e si da via una percentuale di azienda. Questo tipo di investimento introduce immediatamente inevitabilmente degli incentivi spesso mal posti che sul lungo periodo andranno ad intaccare l’esperienza utente. Ma supponiamo che questo progetto comunque vada bene, spesso ci vogliono anni prima di avere un ritorno economico effettivo.
Nel Web3 la storia è diversa. Immaginiamo che qualcuno proponga un progetto basato su un’idea che noi ed altre persone condividiamo e supportiamo. Nel Web3 tutti possono partecipare al progetto dal day-one. La compagnia annuncerà il rilascio di un determinato numero di Token, e darà ad esempio il 10% ad i primi sviluppatori, il 10% in vendita la pubblico, ed il resto da parte per futuri pagamenti.
I detentori del Token, così detti StakeHolders, potranno utilizzare i loro Token per votare cambiamenti o decisioni riguardo il futuro del progetto in cui hanno creduto ed investito dal primo giorno. Gli sviluppatori che hanno contribuito invece, potranno vendere i loro Token una volta rilasciati in modo da ricevere un pagamento per il loro lavoro.
Il tutto è estremamente libero: se supportiamo il progetto, compriamo token e non li vendiamo, il così detto Holding. Se ad un certo punto non ci troviamo più in linea con il percorso che sta prendendo questo progetto, possiamo vendere i nostri token in qualsiasi momento.
Un esempio pratico di applicazione del concetto: un’alternativa non centralizzata a Github.
La differenza rispetto al precedente stato del Web è ormai chiara: quello che succede su internet è in mano agli investitori, non a pochissime grandi aziende come Google e Facebook. È un mondo decentralizzato, i Token Holders sono coloro che controllano il futuro dell’asset e per questo vengono ricompensati: tramite mining nel caso di una Proof of Work, detenendo token nel caso di Proof of Stake (o altre forme ibride).
Identità nel Web 3.0
Nel Web3 il concetto di identità vira in una direzione totalmente diversa da quella a cui siamo abituati oggi: non esistono combinazioni di email + password, preceduti da lunghi processi di verifica dell’identità.
Nella maggior parte delle Dapps la nostra identità è strettamente legata all’indirizzo del nostro wallet che stiamo utilizzando per interagire con il network. Nel caso di una Dapps sviluppata su Ethereum, come ad esempio UniSwap, l’identità sarà il nostro Ethereum Adress.
A differenza dei tradizionali sistemi utilizzati nel Web2, l’identità nel Web3 diventa totalmente anonima, o meglio: pseudonima. A meno che ovviamente non sia l’utente stesso a decidere altrimenti.
L’Ethereum Foundation ha sviluppato un RFP (request for proposal), uno strumento che ci permette di registraci tramite Ethereum.
Smart Contract: lo strumento alla base del Web 3.0
Uno “smart contract” è un semplice pezzo di codice che viene eseguito nella blockchain, ad esempio su Ethereum. Questi “contratti” garantiscono di eseguire un determinata azione e di produrre lo stesso risultato per chiunque lo utilizzi. Li abbiamo visti utilizzati in una moltitudine di Dapps: possono essere integrati in giochi, NFF, sistemi di votazione online e prodotti di tipo finanziario di svariato genere.
Capiamo con un esempio pratico cosa è uno smart contract.
Immaginiamo una classica macchinetta che vende merendine, il più semplice esempio che possiamo pensare. Quella macchina è un sistema hardware, che esegue un determinato programma, un software con delle indicazioni ben precise. Quando inseriamo la giusta quantità di monetine al suo interno ed inseriamo il numero del prodotto, la macchinetta ci restituirà il prodotto scelto.
Allo stesso modo in una blockchain, questi “contratti” posso trattenere del valore, ad esempio sotto forma di Token, che rilasceranno solo se delle precise condizioni decise in precedenza verranno innescate.
Questo concetto esiste da tempo, con l’introduzione delle blockchain e del Web 3.0, siamo riusciti a renderlo trustless. Immaginiamo di fare un scommessa tra amici, il primo a raggiungere 100 punti ad un gioco, vince una determinata quantità di denaro (currency). Ma come facciamo a fidarci che se vinciamo, il nostro amico ci darà davvero i soldi che ci spettano? Fino ad ora per ovviare a questo problema della fiducia, ci si affidava ad un terzo, nel nostro caso un terzo amico. Ma siamo davvero sicuri che questo amico non sia contro di noi, magari è corrotto. Con il Web 3.0 questo problema scompare: una volta deciso il palio di vincita e le condizioni, entrambi i partecipanti depositano nello smart contract la quantità scommessa. Questo bloccherà il denaro e solo una volta che il primo dei due amici raggiungerà 100 punti, lo smart contract darà il palio totale al vincitore.
Conclusioni finali
Con il Web 3.0, ogni persona, macchina o azienda sarà capace di scambiare valore, informazioni e lavoro con chiunque nel mondo, senza bisogno di avere un contatto di fiducia diretto o un intermediario di terze parti.
La più importante evoluzione nel Web 3.0 è la minimizzazione della fiducia necessaria per coordinare operazioni a livello globale.
Il Web3 espanderà in maniera fondamentale la scala e lo scopo delle interazioni tra persone e tra macchine, molto oltre quello che riusciamo ad immaginare oggi. Questo passaggio attiverà una nuova onda di business model fino ad ora inimmaginabili.
© 𝗯𝘆 𝗔𝗻𝘁𝗼𝗻𝗲𝗹𝗹𝗼 𝗖𝗮𝗺𝗶𝗹𝗼𝘁𝘁𝗼
Tutti i diritti riservati | All rights reserved
Informazioni Legali
I testi, le informazioni e gli altri dati pubblicati in questo sito nonché i link ad altri siti presenti sul web hanno esclusivamente scopo informativo e non assumono alcun carattere di ufficialità.
Non si assume alcuna responsabilità per eventuali errori od omissioni di qualsiasi tipo e per qualunque tipo di danno diretto, indiretto o accidentale derivante dalla lettura o dall'impiego delle informazioni pubblicate, o di qualsiasi forma di contenuto presente nel sito o per l'accesso o l'uso del materiale contenuto in altri siti.





